Exploration des possibilités des gaussian splatting pour de la navigation dans de grands paysages.
Capturer et naviguer dans un paysage réel
Dans le vaste éventail des outils technologiques qui ont fleuri ces dernières années du fait du développement accéléré de l’apprentissage profond, à coté des LLMs et les algorithmes de diffusion, d’autres travaux vont probablement transformer leur domaine respectif dans les années à venir.
C’est le cas des neural radiance fields (ou NeRFs), ainsi que la méthode 3D gaussian splatting. Ces deux méthodes, ainsi que leurs nombreux dérivés et améliorations, peuvent être considérées comme des extensions à la photogrammétrie. Il s’agit donc d’utiliser une séquence d’images, issues de photos ou extraites de vidéos, pour être capable de générer une représentation tridimensionnelle de la scène ainsi capturée. Tout comme les applications de l’apprentissage profond mentionnées plus haut, ces deux méthodes reposent sur un processus d’entraînement et d’optimisation / minimisation de l’erreur. Attention toutefois, si les NeRFs sont bien une application de l’apprentissage profond, ce n’est pas le cas de 3D gaussian splatting.
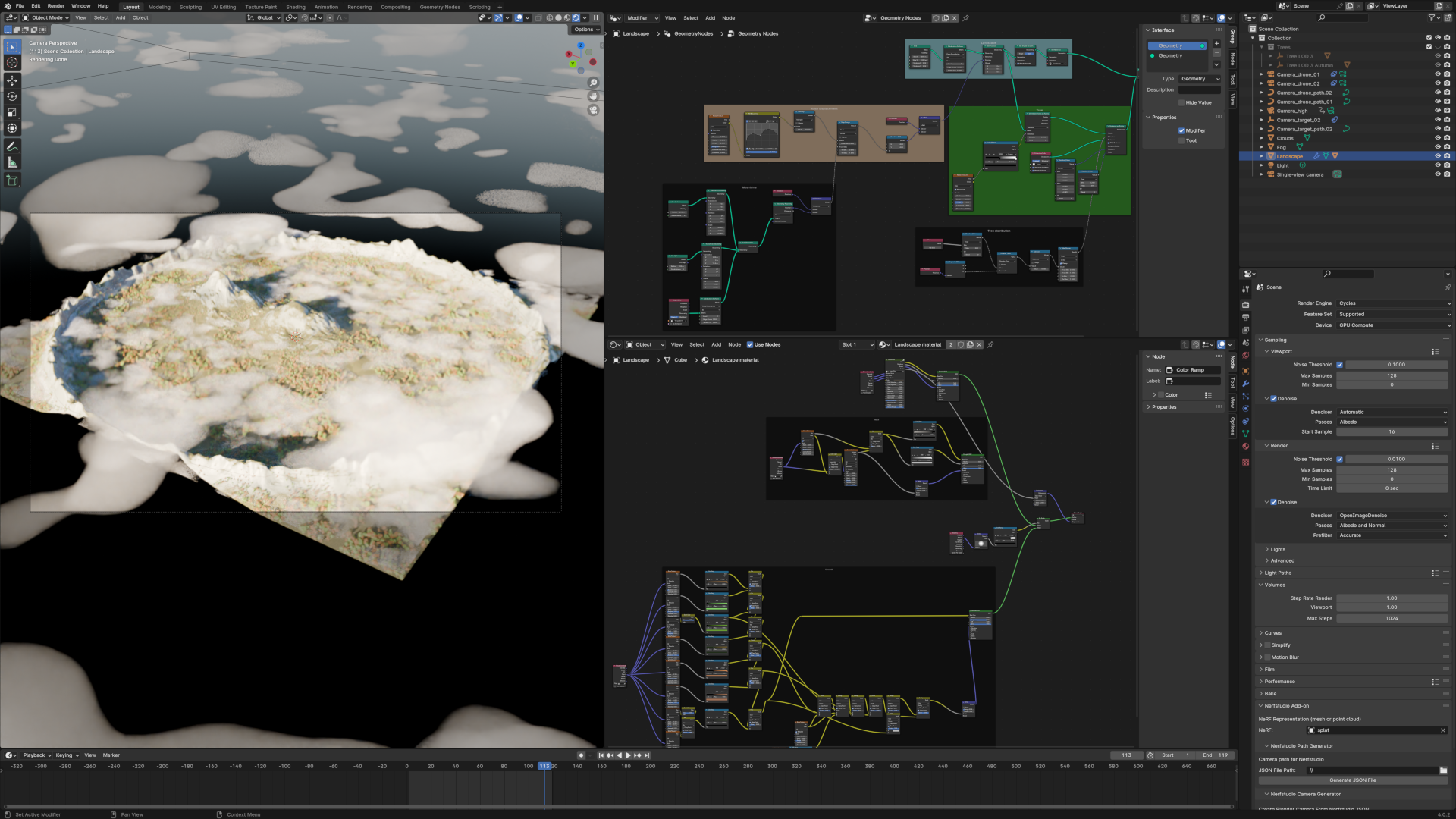
Si le résultat de la mise en œuvre de la photogrammétrie est habituellement un nuage de points ou, idéalement, un maillage texturé (comme le proposent des logiciels comme Meshroom et RealityCapture), les méthodes NeRFs ou 3D gaussian splatting (que je raccourcirai comme gsplat à partir d’ici) proposent pour des représentations sensiblement différentes. Sans entrer dans les détails, les NeRFs vont représenter par l’intermédiaire d’un réseau de neurones la façons dont la lumière se propage dans un volume 3D. Ces méthodes n’ont donc aucune notion de géométrie, mais sont capables de générer de nouveaux points de vue vraisemblables. Quant aux gsplats, ces méthodes peuvent être assimilées aux représentations par des nuages de points, mais en utilisant cette fois des gaussiennes 3D dont les caractéristiques de couleur et de forme (toujours en simplifiant) permettent une représentation plus juste que ceux-ci de la scène capturée. Plus de détails sur les rouages des gsplats peuvent être trouvés notamment sur le blog de Hugging Face.
Dans le cadre d’un projet à venir, nous envisageons de permettre aux visiteurs d’un espace immersif de naviguer librement dans un paysage réel. Du fait de la complexité de la géométrie potentielle et des dimensions du paysage, la photogrammétrie traditionnelle n’est pas envisageable. C’est donc l’opportunité pour évaluer le potentiel de gsplat pour créer une représentation navigable en direct, à partir de prises de vue de drone. Les NeRFs ne sont pas adaptés pour cette utilisation, du fait des ressources de calcul nécessaire pour obtenir un taux de rafraîchissement suffisant, problème que ne présente pas gsplat.
Mise en œuvre de l’évaluation
Pour évaluer cette représentation, nous avons besoin de :
- une suite d’outil permettant de générer et de visualiser les gaussiennes 3D
- une séquence d’images d’un paysage
Pour le second point, n’ayant pas à disposition de drone ni de paysage montagneux, j’ai opté pour une simulation de toute pièce. Cela sort du cadre de cet article, mais j’ai utilisé Blender pour générer un paysage montagneux de 1km². Il existe de nombreux tutoriels sur le sujet, les plus récents tirant parti des geometry nodes pour des résultats plutôt satisfaisant. Pour les curieux, la scène Blender est disponible ici. L’image au début de cet article illustre la scène chargée dans Blender.
Quant au premier point, après avoir fait un état de l’art des outils disponibles, je me suis arrêté sur nerfstudio. Comme son nom ne l’indique pas, nerfstudio implémente plusieurs méthodes de représentation de scène, dont la méthode 3D gaussian splatting. Et contrairement à l’implémentation initiale de l’INRIA qui a une licence libre pour un usage non commercial, celle de nerfstudio est faite sous licence Apache qui permet tout type d’utilisation. Autre avantage, il s’agit d’un projet soutenu par une communauté très active, ce qui présage d’un support sur la durée.
L’installation à proprement parler de nerfstudio sort du cadre de cet article, d’autant plus qu’elle est susceptible de changer avec le temps. La documentation est suffisamment complète pour qu’une personne à l’aise avec le terminal et connaissant l’écosystème Python puisse s’y retrouver. Voici cependant un coup d’œil à ce qu’il est nécessaire d’installer, sur une machine avec un GPU NVIDIA sous Linux (malheureusement nerfstudio ne peut pas fonctionner avec les GPUs AMD) :
# Installation de Miniconda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
# Un conseil : répondez 'non' à l'activation par défaut de Conda,
# pour garder le contrôle sur votre environnement
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
# Activation de Conda, en considérant que vous utilisez Bash comme shell
eval "$(${HOME}/Apps/miniconda3/bin/conda shell.bash hook)"
# Installation de nerfstudio et de ses dépendances
conda create --name nerfstudio -y python=3.8
conda activate nerfstudio
python3 -m pip install --upgrade pip
pip uninstall torch torchvision functorch tinycudann
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
pip install nerfstudio
# Installation de COLMAP, qui est utilisé pour aligner les images
conda install colmap
# Sur certaines machines, COLMAP nécessite CUDA 12.0, donc si c'est votre cas :
conda install -c "nvidia/label/cuda-12.0.0" cuda-toolkit
Une fois installé, la procédure pour générer une représentation à partir d’une séquence d’images est la suivante :
# Activation de l'environnement Conda
conda activate nerfstudio
# Alignement des images, et entraînement
ns-process-data images --data /path/to/image/sequence --output-dir ./work-dir
# Entrainement
ns-train splatfacto --data work-dir
Le résultat de l’entraînement sera stocké dans ./outputs/work-dir/splatfacto/${DATE DE L'EXECUTION}, et il est possible de visualiser la représentation en direct en ouvrant son navigateur préféré à l’adresse https://localhost:7007.
Tests et résultats
Plusieurs trajets de caméra ont été testés, en simulant le trajet que pourrait faire un drone dans un paysage réel. Pour chaque trajet, plusieurs centaines d’images ont été rendues, à des fréquences et des résolutions variables, selon chaque test. Les paramètres qui ont été évalués sont les suivants :
- le type de trajet, et notamment l’orientation de la caméra,
- la fréquence des prises de vue,
- la résolution des prises de vue,
- le nombre de prises de vue,
- le nombre d’itérations lors du processus d’optimisation,
- et le nombre de gaussiennes générées.
Les résultats sont globalement assez impressionnant. La représentation est très intéressante et le rendu est très bon, quoi que aisément distingable des images d’origine. Il reste des progrès à faire pour parvenir à un résultat difficile à distinguer des images d’origine, que ce soit au niveau des algorithmes d’optimisation ou, tout aussi vraisemblablement, de ma propre maîtrise du processus d’entraînement. Voici une animation d’une des représentations obtenues, qui est manipulable de manière fluide sur mon laptop vieillissant doté d’un GPU Intel intégré :

Quelques points sont à garder en tête pour les prochains tests. Tout d’abord la précision de la représentation n’est pas reliée linéairement à la résolution des images. Ce n’est pas une surprise puisque c’est également le cas avec les méthodes de photogrammétrie traditionnelle. La documentation de nerfstudio suggère de se limiter à des images de 1600 pixels de coté (et force par défaut un redimensionnement de l’image dans le cas contraire). Dans mes tests avec des images en 3200x2400, la représentation n’était pas beaucoup plus définie qu’en 1600x1200.
Le taux de recouvrement entre des images successives est un paramètre important. La règle qui dit qu’il faut viser 1/3 de recouvrement entre deux images successives est toujours valide, et si la scène présente de nombreux objets de petites dimensions il ne faut pas hésiter à aller au delà pour qu’ils soient mieux représentés. Aussi, il est important d’avoir de la diversité dans les points de vue, et notamment de tirer parti des changements de parallaxe. Concrètement, cela se traduit par l’importance de privilégier des déplacements orthogonaux par rapport aux objets que l’on veut capturer : les résultats seront moins bons (voire l’entraînement sera impossible) si la caméra pointe dans la direction de déplacement, notamment.
En relation directe avec le taux de recouvrement, il est conseillé de privilégier une caméra avec un champ de vision le plus large possible. Il est même envisageable de faire l’entraînement à partir d’images panoramiques (projection équirectangulaire). Je ne l’ai pas encore testé mais les perspectives sont intéressantes. Voir la documentation de nerfstudio à ce sujet.
Aussi, si on peut avoir tendance à vouloir multiplier les images pour favoriser un grand recouvrement, il faut savoir que ces méthodes sont très gourmandes en mémoire. J’ai ainsi du réserver 48GB de mémoire système lors d’un entrainement avec 780 images en 3200x1600.
Pour donner un peu de perspective quant aux capacités de gsplat, si l’animation précédente est difficile à distinguer de la scène d’origine il est plus évident dans les deux rendus suivants de déterminer celui qui a été fait à partir de la scène Blender d’origine, et celui qui a été fait à partir de la représentations en gaussiennes 3D. C’est évidemment lié aux points de vue des images utilisées pour l’entraînement mais on comprendra aisément que l’utilisation envisagée aura un impact important sur les prises de vues.

Et pour finir, après avoir manipulé les paramètres dans beaucoup de conditions différentes, vient l’évidence : les paramètres par défaut sont un très bon point de départ. Il vaut donc mieux travailler avec ceux-ci et améliorer sa séquence d’image jusqu’à satisfaction, avant de commencer à se plonger dans des expérimentations qui prennent du temps et peuvent être difficiles à comparer.
Pour améliorer les résultats
En parlant de comparaison, je conseille fortement l’utilisation de TensorBoard, qui est un des modes de visualisation de l’entrainement proposé par nerfstudio. Son utilisation nécessite de fouiller un peu dans la documentation, mais en voici les grandes lignes :
# Installation de TensorBoard
pip3 install tensorboard
# L'entraînement doit être lancé avec une autre visualisation
ns-train splatfacto --vis viewer+tensorboard --data work-dir
# Pendant l'entrainement, ou après, lancer TensorBoard
cd outputs/work-dir/splatfacto/${DATE DE L'EXECUTION}/
tensorboard --logdir=outputs/work-dir/splatfacto/${DATE DE L'EXECUTION}/
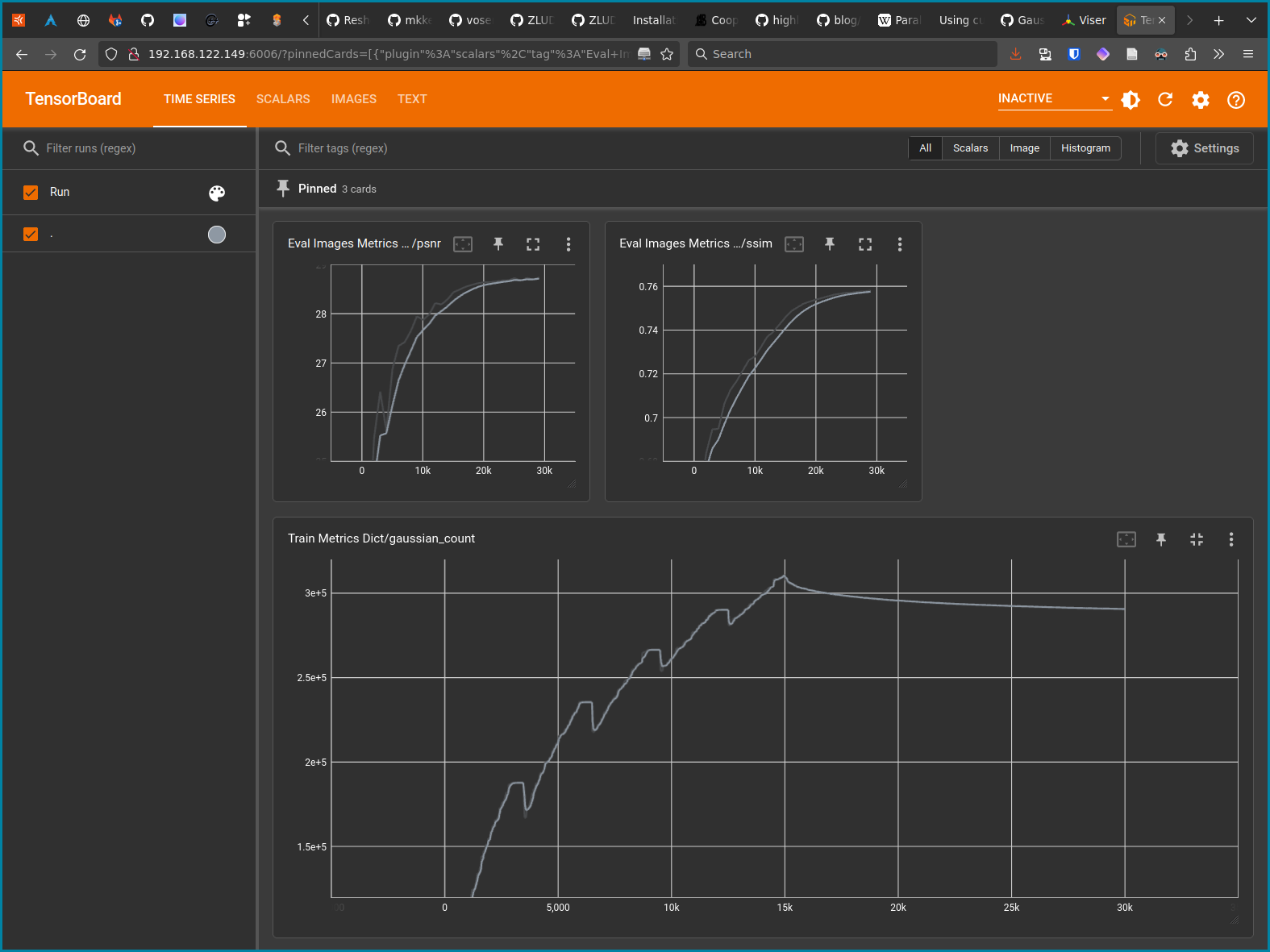
L’interface de TensorBoard sera alors accessible depuis l’adresse https://localhost:6006. Selon mon expérience les principales métriques à suivre sont le SSIM et PSNR dans la section Eval Images Metrics Dicts, ainsi que gaussian_count dans la section Train Metrics Dict. Les deux premières mesures la similarité et le rapport signal sur bruit, et sont une indication de la qualité de la représentation. La troisième indique tout simplement le nombre de gaussiennes de la représentation, ce qui aura une incidence directe sur sa taille et les performances lors de sa visualisation. Dans l’image suivante, on peut voir que le SSIM et le PSNR augmentent progressivement jusqu’à atteindre un plateau :
Notes de fin
Après ces quelques tests, je suis toujours aussi convaincu que les gsplats vont avoir de nombreuses applications et une grande influence sur le monde de l’informatique graphique et de la réalité virtuelle dans les années à venir. Tout autant que les NeRFs d’ailleurs, même si pour l’instant ceux-ci sont difficilement manipulables en temps réel.
Il y a de nombreux points que je n’ai pas couvert dans cet article, et en particulier tout ce qui touche à l’utilisation dans d’autres logiciels. Il existe des addons pour plusieurs, les plus avancés étant actuellement destinés à Unreal Engine, notamment XV3DGS-UEPlugin, 3D gaussian splatting rendering for UE et l’addon de Luma-AI.
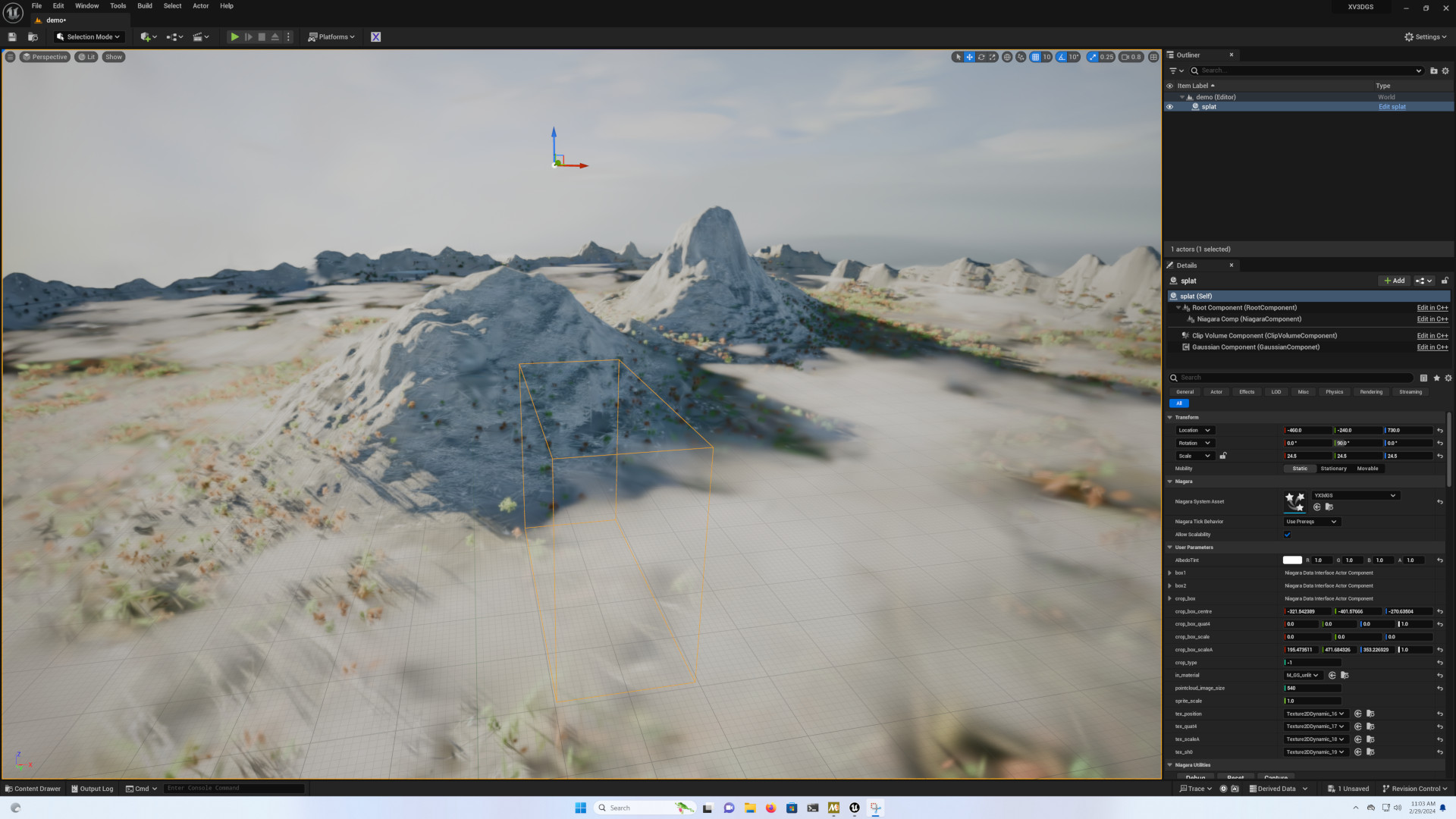
La situation est moins florissante pour les autres outils, même si la situation va très certainement s’améliorer. On peut tout de même citer l’addon Gaussian splatting pour Blender. Pour plus de sources sur le sujet, je vous conseille le dépôt très complet Awesome 3D gaussian splatting.