Experimentation montrant la faisabilité de la transformation sonore de la surface d’un bureau en instrument de percussion à l’aide de la suite d’outil RAVE.
Ah ! un outil pour la génération en direct de son par modèle d’intelligence artificielle : RAVE. Peut-on l’entrainer avec ses propres données ? En local sur sa propre machine ? Est-ce que l’on reconnait les sons utilisés pour l’entrainement ? La latence est-elle basse ?
La réponse est oui à toutes ces questions. Pour en savoir plus, voici une vidéo résumant mes expérimentations, en utilisant le son de mes doigts qui frappent sur mon bureau pour contrôler la génération sonore en direct.
Pipeline
Le principe est assez similaire aux autres outils d’intelligence artificielle : à partir d’un ensemble de fichiers audio, il est possible d’effectuer un entrainement, qui produit un modèle. Ce modèle est disponible dans un fichier, qui peut alors être utilisé dans un outil qui permet d’appliquer les sons utilisés lors de l’entrainement au son envoyé en direct.
Il y donc deux phases, la production du modèle et son utilisation. Pour l’entrainement, RAVE met à disposition plusieurs modèles, dont la qualité est bien supérieure à celle que j’ai pu produire en entrainant un modèle pendant 24 heures. Pour l’entrainement, j’ai utilisé une heure de mes enregistrement de Udu, un instrument à percussion en forme de Jarre.
Pour l’utilisation du modèle, j’ai utilisé un microphone de contact, sous forme de pince, fixé sur la surface de mon bureau. Ce signal sonore est alors offert en direct au couple encodeur/décodeur dans le patch PureData.
Qualité du Rendu
Deux choses : la qualité du son et la latence. Le modèle que j’ai produit et utilisé est certainement améliorable car l’entrainement n’a roulé que pendant 24 heures environs. Les modèles fournis en exemple avec RAVE ont été entrainé avec des sons issuent d’enregistrement de très bonne qualité, et cela s’entent lorsqu’on les utilise.
Pour la latence, il y a plusieurs facteurs qui peuvent jouer. La latence du pilote de la carte son, que je n’ai d’ailleurs pas cherché à optimiser, et la latence de traitement du modèle. C’est cette dernière que j’ai mesuré avec le patch suivant :
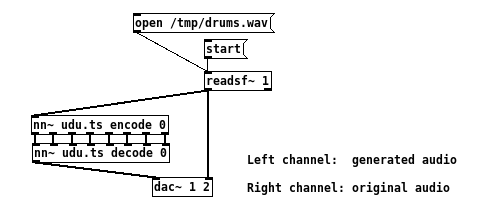
En quelques mots, un fichier de percussion est joué, puis son signal est envoyé aux objets nn~ (encodage/décodage) qui générent un signal similaire, mais basé sur les sons utilisés durant l’entrainement. Finalement, les deux signaux sont routés vers deux canaux de sortie différents : “canal de gauche” pour le signal produit à partir du modèle et “canal de droite” pour le signal original.
Avec cela, les deux signaux peuvent être enregistré simultanément dans un séquenceur, et il est donc possible de mesurer approximativement le délai entre un coup de percussion et son rendu produit avec le modèle. Voici la mesure :
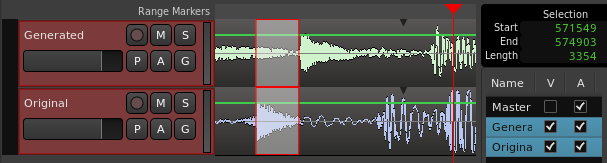
Comme l’indique la zone en haut à droite, le délai (la sélection) correspond à 574903 - 571549 = 3354 samples, échantillonés à 48KHz, soit une latence de 70 millisecondes. C’est certainement trop grand pour reproduire la sensation d’instantanéité lors des frappes sur la surface, mais cependant suffisamment bas pour donner la sensation d’interagir en direct avec le son.
Dernières remarques
Malgré les critiques, je reste impressionné par la qualité du rendu et par les performances de RAVE avec nn~. Le résultat et la “facilité” de mise en place du pipeline ouvrent des possibilités d’interactions sonores nouvelles, et qui restent à imaginer. Merci Antoine Caillon, Philippe Esling, l’IRCAM et toute l’équipe de RAVE !