Experiment demonstrating the feasibility of transforming the surface of a desk into a percussion instrument using the RAVE tool suite.
Ah! a tool for live sound generation using an artificial intelligence model: RAVE. Can you train it with your own data? locally on your own machine? do you recognize the sounds used for training? is the latency low?
The answer is yes to all these questions. To find out more, here’s a video summarizing my experiments, using the sound of my fingers tapping on my desk to control live sound generation.
Pipeline
The RAVE usage logic is quite similar to other artificial intelligence tools: from a set of audio files, it is possible to perform training, which produces a model. This model is available in a file, which can then be used in a tool that applies the sounds used during training to the sound sent live.
There are therefore two phases: the production of the model and its use. For training, RAVE provides several models, whose quality is far superior to what I was able to produce by training a model for 24 hours. For training, I used one hour of my recordings of Udu, a jar-shaped percussion instrument.
To use the model, I used a contact microphone, in the form of a clip, attached to the surface of my desk. This sound signal is then used to feed the encoder/decoder pair in the PureData patch.
Rendering Quality
Two things: sound quality and latency. The model I produced and used can certainly be improved, as the training only ran for around 24 hours. The models supplied as examples with RAVE have been trained with sounds from very good quality recordings, and you can hear this when you use them.
As for latency, there are several factors at play. The latency of the sound card driver, which I didn’t try to optimize, and the processing latency of the model. I measured the latter with the following patch:
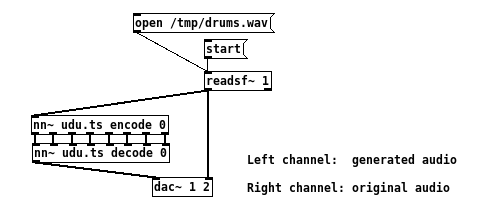
In a few words, a percussion file is played, then its signal is sent to the nn~ objects (encoding/decoding) which generate a similar signal, but based on the sounds used during training. Finally, the two signals are routed to two different output channels: “left channel” for the signal produced from the model and “right channel” for the original signal.
With this, the two signals can be recorded simultaneously in a sequencer, and thus roughly measure the delay between a percussion hit and its rendering produced with the model. Here’s the measurement:
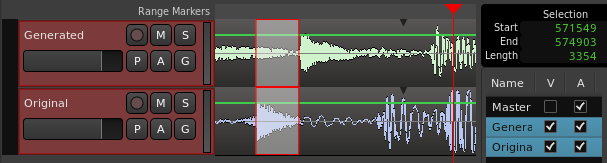
As shown in the top right-hand corner, the delay (selection) corresponds to 574903 - 571549 = 3354 samples, sampled at 48KHz, i.e. a latency of 70 milliseconds. This is certainly too high to reproduce the sensation of instantaneity when striking the surface, but low enough to give the sensation of interacting directly with the sound.
Final comments
Despite the criticisms, I remain impressed by the quality of the rendering and by RAVE’s performance with nn~. The result and the “ease” of setting up the pipeline open up new possibilities for sound interaction, which have yet to be imagined. Thank you Antoine Caillon, Philippe Esling, IRCAM and the whole RAVE team!